
前言
在甲方待了一段时间发现,在企业中想要提升安全性或者落地某个新的安全能力,总是需要和业务性能进行对比。如果某个安全特性的性能开销过大,那么对于业务来讲是一种不可接受的代价。因此,安全从业者学习一点性能优化的手段也是非常重要的。这里博主主要在操作系统领域,相关的代码主要以C为主,所以性能优化也是围绕着语言相关特点。
C语言从代码到可执行文件,再到最终的运行阶段,主要是两个部分组成——编译阶段和执行阶段。针对编译阶段,我们能做的就是尽可能的利用编译器特性和特殊编码技法来优化;执行阶段涉及到指令的热点运行,由于程序执行的局部性原理,我们的大量代码在执行时往往会重复一小段逻辑。因此,性能优化的重点就是在于这些热点函数之中。对于非热点函数,我们则更加关注体积,怎么写能够使得代码编译出来的指令数最少,减少对空间的占用。
以下则从六种不同的角度,针对C语言程序做优化。
编译选项
对于非编译器开发的程序员来说,新增一个编译选项就能搞定的事情,肯定是非常之轻松的活。
通用编译优化 -O
编译器一般会默认一个优化等级,但当我们想要朝着更优的方向前行时,就需要将优化等级调高。这里在编译Linux内核时,默认是-O2,其他平台类二进制需要关注项目本身的设置。如果觉得-O2的效果一般,可以尝试-O3。
指令架构优化 -march
编译器针对不同的指令集以及cpu架构都有着极强的针对性优化(搞编译优化的人是真的顶),比如这里的-march=x86-64-v3 就是针对v3版本的x86-64指令集做专属优化。除了指令集还有cpu架构,比如经典的奔腾,haswell,还有i7等等。同理在ARM架构上也有类似的参数可控选择,根据不同的ARM指令集版本也有不同的参数。
更多细节可参考:
x86 https://gcc.gnu.org/onlinedocs/gcc/x86-Options.html
arm https://gcc.gnu.org/onlinedocs/gcc/ARM-Options.html
链接优化 -flto
通过把很多编译优化放在链接阶段执行,实现范围更广的优化面。
-flto 可以在编译时进行全局优化,但整体的时间开销和编译资源开销将大大增加,而 -flto=thin 是一种折衷方案,它在链接阶段进行优化,同时减少了编译时间和资源消耗。
链接优化的目标:
- 内联函数:优化开启之前只能针对单一C源代码优化,开启后能针对全局整体做内联优化
- 函数重定位:能通过静态分析调整函数代码位置,减少函数调用链长度
- 代码融合:多个代码块合并,减少代码的执行次数
- 数据流分析,移除不必要的死代码
总的来说,链接优化能在全局层面做到更好的优化方案,减少代码体积和增强程序性能。
关闭安全选项(不推荐)
作为一个安全从业者,非常的不推荐关闭这些安全选项,反而推荐去开启一些额外的安全编译选项来增强安全能力。但是,在某些性能要求的特殊场景下,确实会关闭某些安全能力来提升性能。
以下列举一些关闭的方式,但还是要说,这是饮鸩止渴。
-fno-sanitize=all关闭所有的消毒器-fcf-protection=none关闭编译器自带的控制流保护-fno-harden-compares关闭针对比较操作的防溢出处理-fno-harden-conditional-branches关闭针对条件分支的安全增强-fno-harden-control-flow-redundancy关闭控制流冗余检测的安全增强-fno-hardened关闭一系列的安全增强选项-fno-stack-protector关闭栈溢出保护机制-fno-stack-check关闭栈的边界检查功能-fno-stack-clash-protection关闭栈冲突保护-fno-stack-limit关闭栈大小限制约束-fno-split-stack关闭栈切割的安全增强-fstrub=disable关闭编译器中的结构化控制流保护
编码优化
以下给出的代码示例,均通过在线的编译器网站进行编译反汇编转换。
编译器:ARM64 gcc 7.3
局部变量缓存
缓存多次访问的全局变量
当我们有多次访问全局变量的需求时,不要多次使用全局变量,而是把全局变量读出后放入局部变量中,之后的读写都对该局部变量进行,最后的结果数值写回全局变量中,这样能避免频繁的内存空间访问,直接使用栈上的寄存器值。
1 | int sum = 0x1234; |
这里如果有反汇编,就能看到每次读sum时都需要访问一次程序中的全局数据段。
1 | sum: |
如果将其存放进局部变量中,那么我们的值将会通过栈上的数据存储,在完成数据修改后再写回全局变量,这样能减少无效的内存访问,优化程序整体的速度。
1 | int sum = 0x1234; |
优化之后的反汇编结果:
1 | sum: |
缓存多次使用的表达式
非常显而易见的事情,如果在编码中出现了多次的表达式,就应该用局部变量缓存一下,而不是用相同的语句再计算一遍。下面给了一个例子,我们在做计算的过程中,类似于value_1 和 value_2这样的表达式结果,如果后续还有使用的场景,在不影响最终结果的情况下就应该直接复用。
1 | int func(int a, int b) |
以上代码可以优化为下面的样子,当然这个地方编译器估计也能有点优化,但能优化到什么程度全看用的什么编译器,以及编译器的版本和编译选项。所以,这种能依靠编码优化的情况,尽量在代码实现时就完成最优处理。
1 | int func(int a, int b) |
标记条件分支
__builtin_expect
这个编译器内置的函数,能够标记最有可能进入的条件分支,而这个最常进入的条件分支的语句指令会被放在前面,不常进入的语句指令将会被放在后面,如此一来,可以最大化的发挥CPU的指令预取能力。__builtin_expect在很多时候也会被封装成LIKELY和UNLIKELY的宏,需要根据你所在的编码环境具体选择。(需要添加-O2的编译选项才能触发标记条件分支的优化)
具体用法如下:
1 |
|
分别编译以上两段不同的程序,我们通过反汇编就可以查看到,当条件语句为LIKELY(a > 5)时,上面的a -= 5;b++;是在比较指令cmp的后面;
1 | cmp w0, 5 |
当条件语句为UNLIKELY(a > 5)时,下面的a += 5;b--;就会被放在指令cmp的后面。这样的结果,也对应了代码局部性原理,让更可能执行的指令放在一起。
1 | cmp w0, 5 |
__builtin_unreachable
同样为编译器内置的函数,能够标记分支中明确不可达的部分,这样能让编译器感知到该分支永远不可达。(那么永远不可达的代码为啥还要写呢?这又是另外一个问题了,某些场景是为了程序员方便理解,某些场景是为了清除编译告警等问题)针对这类标记,编译器在感知到不可达信息之后,能够使用更加激进的优化方案处理这段代码的指令翻译。
具体用法如下:
1 | void __noreturn arm64_serror_panic(struct pt_regs *regs, unsigned long esr) |
我这里直接拿了一段Linux内核的代码来举例子,这里有个场景是陷入循环中,永远不会退出。在这种场景下,末尾跟随一个unreachable表达后面永远不会到达。这样编译器,就能针对这个点单独做出优化,比如这样就不需要在函数末尾出栈和返回,以及针对性的做出指令地址布局的优化。
static_branch_likely 和 static_branch_unlikely
在内核中有着两个神奇的宏定义在include/linux/jump_label.h中,这就是static_branch_likely和static_branch_unlikely。这两个宏定义配合Linux内核的跳转表能玩出特别花的动态分支调整,这里的两个宏实际的用法,和上面的LIKELY和UNLIKELY是一样的,在条件判断中添加后用于优化编译后的指令布局。但它强大的地方在于,还提供了另外的接口static_branch_enable和static_branch_disable控制这种优化(还有static_branch_inc和static_branch_dec),在满足特定场景和条件的情况下,开启/关闭分支优化。
下面来看示例代码(从Linux内核摘抄,kvm模块的代码):
1 | static DEFINE_STATIC_KEY_FALSE(has_gic_active_state); |
在文件的最开头定义这个动态条件变量默认为false,在初始化的函数中判断是否存在gic,在拥有的情况下会开启这个动态分支优化。下面在kvm模块使用的接口中,会利用static_branch_likely接口判断这个条件变量的使能情况,在上面使能后这里就能通知编译器针对性的优化,如果没使能这里就会按照正常的条件分支做编译处理。
switch的表跳转优化
写代码过程中常见的“垃圾”代码就是一大串的if-else分支,如果是特别清晰的判断逻辑可能还能接受,一旦判断条件很复杂,简直就是一坨屎山。在这种大量if-else的场景下,也有一种对应的优化手法,那就是转换成switch-case的模式,而超过某个case数量阈值的switch-case能够被编译器自动优化成跳转表的指令格式,这能大量压缩指令数量以及增加条件判断性能。当然,这里你也能手动把if-else改造成跳转表格式,不过这会有点点烧脑,需要构造一会儿。
以下一段代码示例:
1 | int func(int input) |
这段代码如果编译出来后,反汇编查看指令,就能看到其中的if-else全部被转为了cmp指令,会进行多次cmp比较,通过比较的逻辑判断出要跳转的位置,再去执行对应分支上的逻辑。
1 | func: |
优化之后,采用switch-case的模式的代码如下:
1 | int func(int input) |
这样再次编译的时候,查看它的反汇编结果,就能看到生成的跳转表(在末尾):
1 | func: |
注意:
关于这个跳转表优化,我在实际测试的过程中发现它和编译器的版本强相关。在比较新的编译器clang或者gcc高版本上做测试时,在不开启高优化选项时,也能针对if-else分支做跳转表优化。这说明编译器本身的优化能力也是在版本升级的过程中,不断地增强迭代。可能现阶段使用较新编译器的情况下,该条优化建议所能产生的价值较为有限。
循环行为优化
提取循环中的无关操作
使用了循环语句,说明循环内部的操作是需要反复执行的内容,这段内容越精简也会使得整体的效率越高。但是如何精简呢?方向大致上是:
- 循环的判断条件
- 循环体内的计算
如果存在每次循环中都是相同的内容,可以抽离出循环体外。给一段示例代码:
1 | void func(int *a, int *b, int num) |
优化其中共同的计算内容后:
1 | void func(int *a, int *b, int num) |
地址小偏移和多次数循环尽量在内层
可以结合cache优化章节的内容一起学习,这里将地址小偏移以及循环次数多的内容放在循环内层中,为了更多的保证cache的命中率,同时内层循环次数多,外层循环次数少,也就意味着外层的条件判断相关内容执行的少,这样反而能少一点循环变量初始化的指令执行。
示例代码如下:
1 | for (int j = 0; j < 1000; j++) { |
优化之后的代码,把循环的遍历方式调整为以行遍历为准,以列遍历的方式一方面会增加循环变量的初始化次数,另外一方面会减少cache的命中率(详细见cache优化章节)
1 | for (int i = 0; i < 10; i++) { |
循环合并
顾名思义,将多个相关联的循环语句合并为一个循环语句,这样带来的好处是判断条件导致的开销只会剩下一个循环的,不会有其他循环的条件判断指令造成额外开销。但这是一把双刃剑,循环体内部的语句膨胀之后,会造成指令cache命中率下降,这会是另外一种形式的性能损耗。
示例代码如下:
1 | for (int i = 0; i < num; i++) { |
优化之后的代码,将两个循环合并为了一个循环。
1 | for (int i = 0; i < num; i++) { |
函数设计
少用结构体等大数据类型的直接参数传递
在C语言中参数传递的方式,主要有值传递和指针传递。其中值传递的方式,是会将参数传递的值拷贝到栈空间上暂存,这会导致两个问题。一是拷贝数据的动作会造成性能开销,二是暂存在栈空间也是对栈的消耗,当传入的结构体超大时容易出现爆栈情况。而对于指针传递,只需要考虑指针的大小,这通常为4字节(32位)/8字节(64位),不需要占用过多的拷贝时间,也不需要特别大的栈空间开销。
示例代码:
1 | struct my_struct { |
从传入结构体修改为传入指针类型,但更好的方式是在这种只读场景下添加const修饰符,把它当做常量来使用。
1 | struct my_struct { |
性能敏感路径上的函数内联
函数内联是一种非常常见的优化手段,在各种开源项目中都会有一些inline修饰符的函数,这个就是选择了内联的函数。内联函数在编译之后会被展开,也就是说在完成编译后这个函数会消失,在调用点变成相应的执行语句。这个的好处,显而易见的是没有了函数压栈和出栈的开销,在性能敏感的路径上少几条指令就会迎来质变。
1 | static inline void hot_func(int value) |
使用函数内联也会带来一些风险和麻烦。
- 调试的麻烦。函数内联后,在获取二进制进行反汇编或者用gdb调试时不一定能精准的识别出这里的代码位置,在标记内联后编译器还会做一些优化处理,这会使得调试信息符号可能出现问题。
- 热补丁的麻烦。有些程序为了运行稳定,需要使用热补丁做动态程序漏洞修补,函数内联后会更加难以定位出具体的代码位置,如果是内联函数出了漏洞bug,将难以直接热补丁修复。
- 体积上的风险。这里函数内联的本质和宏定义展开是类似的情况,它是不会复用这段代码指令,而是把调用点全部替换为相同的执行语句,这就会带来程序体积上的增长。
结构体设计
这点在设计结构体成员的时候就有所体现了,大部分常见的开源软件,他们的结构体设计都是相关联的成员变量离得很近,这也是为了CPU里的数据cache加速。当我们访问结构体时,成员变量靠近就会很大概率存储在同一个cache里,这样访问其中的数据就不会导致cache未命中。相反,如果在设计结构体时,两个变量离的很远,就会造成cache未命中,引起CPU内部的cache刷新,降低了数据访问性能。
示例代码如下:
1 | struct key_value_list { |
优化之后,把其中的公共字段提取出来,成为一个单独的结构体,然后再声明一个新的数组。这样,每次访问结构体的key和value,都在附近的位置。
1 | struct key_value_pair { |
简化冗余行为
不必要的初始化行为
如果某个变量声明后做了初始化,第一次使用也是直接对其做赋值,那么这个初始化的行为则没有意义。针对这种情况,在变量声明时就不应该做初始化动作,这样能节省初始化的开销。
示例代码:
1 | int func(void) |
在初始化sum之后,马上又对其做赋值,这里就能直接优化掉sum的初始化。
1 | int func(void) |
减少内存段擦写
在程序中大量的memset和memcpy等行为,会严重拖慢整体的速度,所以这种内存段擦写和拷贝动作,需要考虑他们的重要性。针对安全性不高的临时数据,没必要在每次操作前都覆盖一遍。
针对字符串,可以通过末尾的\0来截断字符串的解析,以此屏蔽字符串末尾后面的无效数据。
1 | int init_func(void) |
注意:密钥,密码,校验hash值等安全相关的缓存数据,应该要及时清理。
减少重复计算
这点和上文提到的利用局部变量缓存的机制很类似,局部变量缓存也是实现减少重复计算的方式之一。除了局部变量减少重复计算,还有全局变量,静态变量或者常量的方式。这些动作的优化,都是为了减少重复的工作量,提升程序整体的计算性能。
示例代码:
1 | int func(void) |
优化之后,同样使用局部变量的方式替换重复的计算过程。
1 | int func(void) |
条件判断的短路效应
在C语言的逻辑判断中如果是与(&&)的逻辑判断,在其中第一个条件失败时就不会再进行后面的条件计算,这就是短路效应。利用这种短路效应,也是一种能够节省计算的方法,能减少一部分表达式的求值计算。与此对应,或(||)的逻辑判断中,只有当第一个条件判断失败之后,才会进行第二个条件的计算。
以下示例代码中展示了一个条件与的判断场景,check_a和check_b的两个逻辑判断。这里,check_a如果失败的可能性比check_b更大,那么它就应该放在前面,这样它一旦失败之后,就不会再判断后面的条件内容check_b了。
1 | void func(void) |
cache优化
非常推荐陈浩大佬写的CPU缓存知识文章,里面从浅入深讲述了CPU的cache知识。里面举例了几个经典的cache案例,涉及体系结构中的CPU设计,包括CPU cache line大小和CPU ways数量。有个网站叫做wikichip,能够查询CPU的基本信息,其中有缓存大小和ways数量,但没cache line的描述,估计大部分主流CPU都是64字节的设计,我自己的macbook-15 2018款i7的信息是Core i7-8750H。
这里提到的cache优化主要分为两个方面:
- 数据访问步长过大导致的cache命中率低下
- 多线程场景下写入共同数据时,多核CPU间相同cache数据同步导致的cache利用率不高
访问步长导致的cache问题
直接上代码,这里用了两层循环,外面一层循环为执行10000000次任务,里面一层循环是以increment的步长,每轮任务count次数来访问memory数组中的数据,并写入新的内容。
1 | for (int i = 0; i < 10000000; i++) { |
首先,引用陈浩大佬的通俗计算公式。
Intel 大多数处理器的L1 Cache都是32KB,8-Way 组相联,Cache Line 是64 Bytes。这意味着,
- 32KB的可以分成,32KB / 64 = 512 条 Cache Line。
- 因为有8 Way,于是会每一Way 有 512 / 8 = 64 条 Cache Line。
- 于是每一路就有 64 x 64 = 4096 Byts 的内存。
这里能够知道大部分场景下,设计出的一路缓存Cache是4KB的大小,这也刚好和大多数的页大小一致。因此,如果这里的count大于8,increment为1024,也就是4KB的步长,就会出现所有的Ways被用完的情况,从而引发cache冲突失效。
同理,还有另外一种二维数组的遍历场景。逐行遍历和逐列遍历的方式在性能上也会出现跨列时步长过大,引起cache大量冲突失效的问题。
1 | const int row = 1024; |
针对这种场景出现的性能问题,我们的优化方案会很直接。
- 优化步长。如果步长能够被压缩,则尽可能的小,以此能在同一个4KB缓存中出现。
- 优化遍历方式。尽量实现连续的内存访问,而不是跳跃式的内存访问。
多线程写入导致的cache问题
第二个可能出现cache问题的情况,是多个线程去访问了相邻的数据内容,并且其中有写入行为。
1 | void fn (int* data) { |
由于Cache Line 是64 Bytes,这里的p[0]和p[1]都在同一块Cache中,而这里多线程反复修改会造成CPU Cache失效,多线程任务会跑在不同核的CPU上,这就使得CPU之间的Cache需要做同步,这种同步产生在两个CPU的L1和L2 Cache中,效率严重下降。
如果将p[1]替换为p[30],30和0之间的差距30 * 4 = 120 Bytes,这就使得两个不在同一块Cache中,分别对其做更新写入时不会影响另外一块Cache的情况。
大部分的CPU模型是分为L1、L2、L3三层模型,其中L1和L2是单核使用,L3一般是所有核公用。上方的多线程读写就会使得不同核心间的数据产生差异,CPU在处理这种场景时就涉及到数据状态标记的状态转换。再次引用陈浩大佬的介绍内容,用一个最简单的状态协议做个初步介绍,更详细内容建议阅读原文。
这里介绍几个状态协议,先从最简单的开始,MESI协议,这个协议跟那个著名的足球运动员梅西没什么关系,其主要表示缓存数据有四个状态:Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的)。
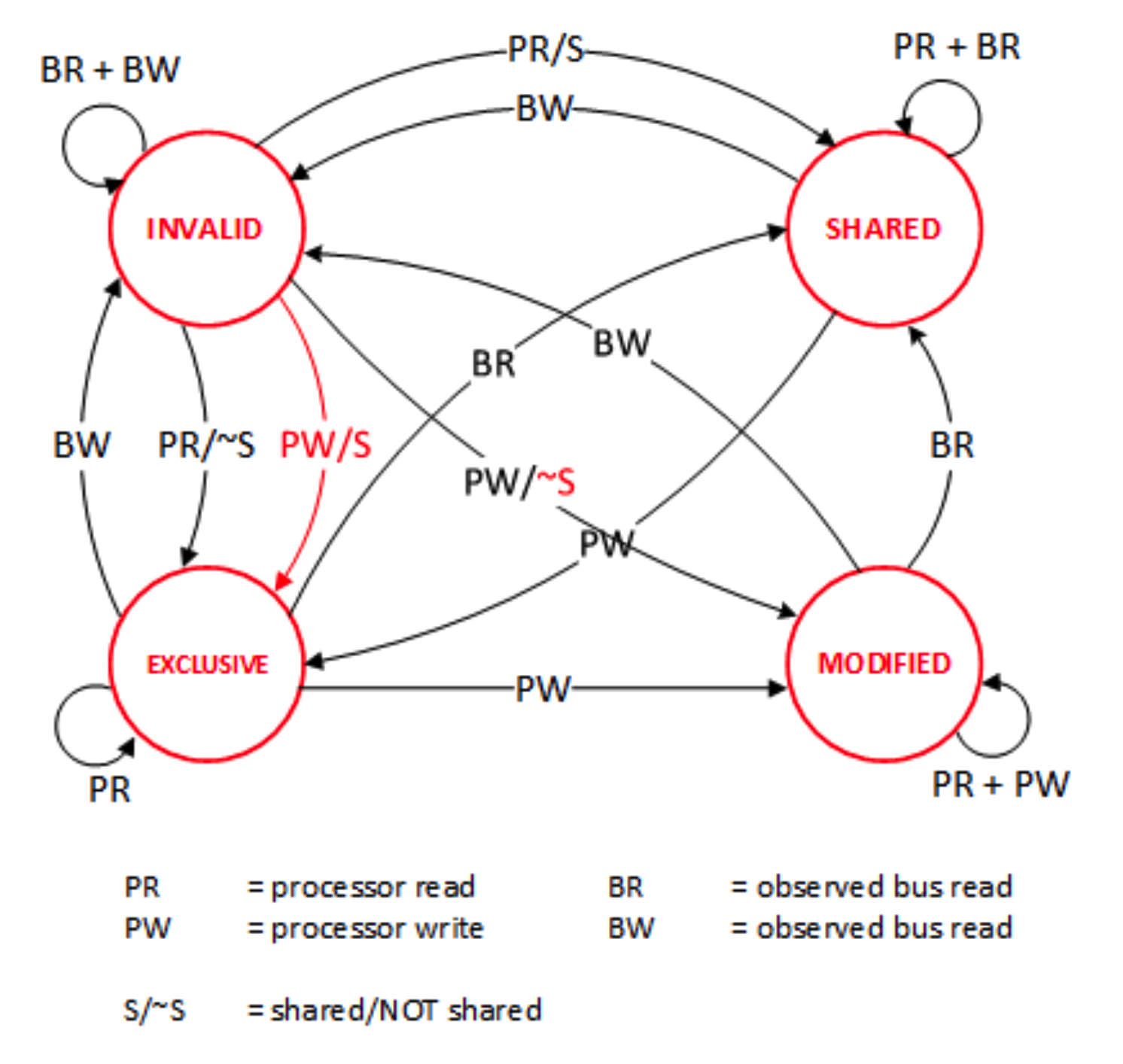
强大的MESI动画网站,清楚的展示了不同CPU之间的数据读写如何同步 https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
一些趣事
根据我自己的经历,cache优化还和指令对齐相关。这里提两个我在工作上遇到的两个性能问题:
一个是在某产品的特定硬件上出现了性能普遍劣化1.5-2%,而这个劣化是由于top工具的采样不准确导致的。在不断地测试中发现,这个不准确是因为采样频率刚好和进程切换相撞,让top统计时认为该进程还在运行,但实际上运行时间并没有那么长。最后是强行用了一种trick的方式,强行加无效指令做对齐让top统计结果恢复正常。
第二个是我手上看护的某个特性,会在程序中做指令级插桩,而插桩的内容中刚好包含align对齐指令。这个对齐通常情况下不会有额外的副作用,但在某些特殊情况下会因为对齐使得某部分代码刚好超出页大小,在执行相关流程时需要多分配页外加是性能敏感路径,这就导致性能下降。
并发处理优化
并发的无锁实现
无锁实现指的是通过限制某个变量只能被特定的对象访问,以此来取代需要加锁保护再来访问的情况。控制访问来源,这样在并发场景下就无需再加锁。这种实现能避免复杂的加锁解锁的代码,简化了代码逻辑又能保持良好的可维护性,为后续的功能开发不会带来太大的历史包袱。
单生产者 单消费者模型
这种模型的理念是有多少个生产者就对应有多少个消费者,并且某个生产者A生产的内容,只会被对应的某个消费者a获取,别的消费者b无法访问生产者A的内容。简化成示意图如下:
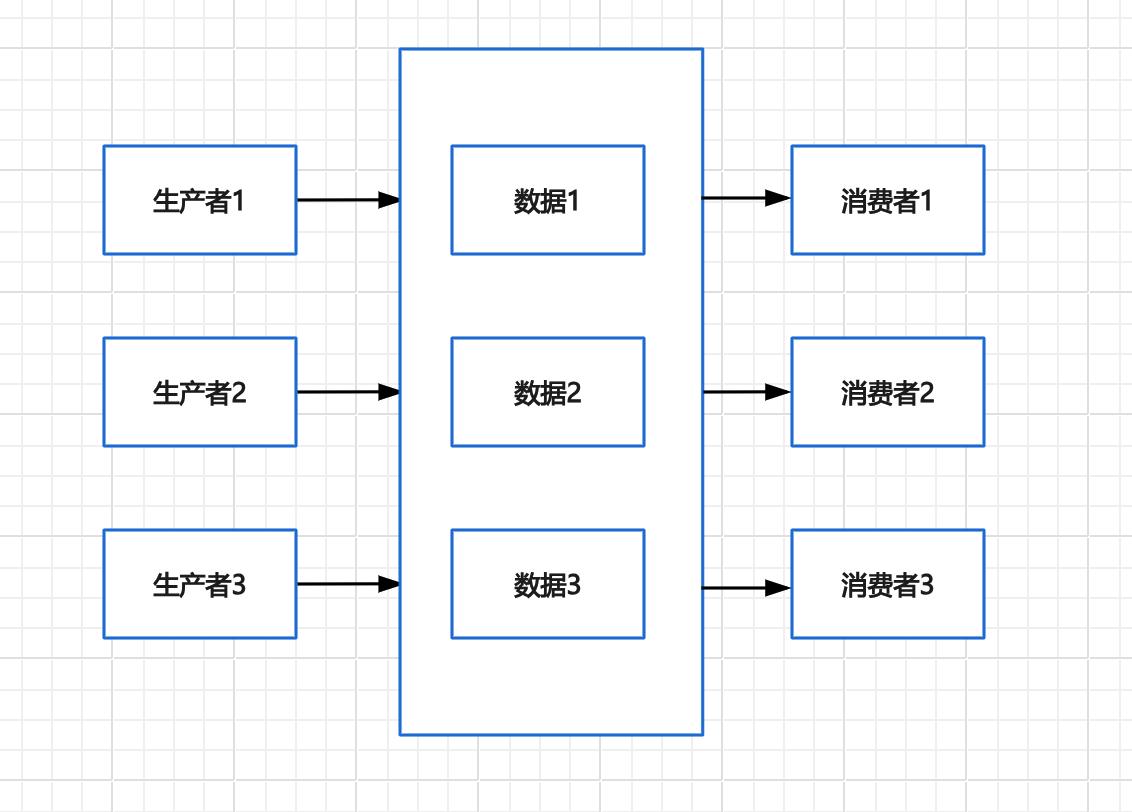
在这种场景下,每个生产者和消费者都是依靠索引访问,这样每对生产者消费者不会互相干扰,在这样的并发情况下,也是由多个线程去执行多对不同的生产者消费者流程,可以不用加锁去保护其中的数据内容。
线程变量
gcc中提供的关键字__thread,可以用于线程级别的变量。被__thread标记的变量在每个线程中都是一份独立的存储,这样能使得线程之间不会互相干扰。在这种情况下,多线程并发时,对于这种线程变量的读写访问是不需要加锁保护。
但该关键字存在一些限制与约束:
- 只能修饰基础数据类型,不能修饰复杂数据结构(比如结构体、类等)
- 不能修饰函数局部变量或者类的普通成员变量
本质上是对一些全局性的变量做标记,比如全局变量和静态变量。让编译器能自动帮助程序员使用空间换时间,得到更大的性能。
CPU变量
Linux内核中提供的一个神奇机制PER_CPU变量,为每个CPU都创建变量的独立副本。这样在跑多线程任务或者多进程任务时,每个CPU所访问到的都是唯一的副本。这里的设计和上面的线程变量__thread非常类似,都是用时间换空间的典型。
具体的代码实现,面对定义为PER_CPU的变量,内核会根据CPU的数量创建对应大小的数组,每个CPU只会访问其中的一个元素,这样CPU之间的任务不会互相干扰。
当然有的人可能会和我一开始了解时有着同样的疑问,这个明明是针对CPU的变量,为啥也可以做到无锁且不会有并发问题?原因是这里一旦开始访问PER_CPU变量时,内核会关闭该CPU的抢占,这样在该CPU上执行的任务就不会被其他高优先级进程抢占,当进程切换出去后,又被切到另外一个CPU上导致数据出现同步问题。
使用这种CPU变量需要注意的点是需要用内核提供的专用API接口,包括变量的定义,变量的指针提取,读取变量的值,释放变量等等。
注意
现代CPU中的乱序执行会影响以上的优化方案,最经典的例子就是内存操作中出现的乱序执行,造成程序出现预期之外的行为。
比如,先对某个变量写入一个值,再读取这个变量,一个典型的单生产者单消费者场景。如果出现了乱序情况,就会出现读取操作在写入之前。当然,这里的例子比较极端,单变量访问出现的可能性比较小,一般是复杂的结构体数据或者是大段数组空间写入时,会出现乱序执行造成异常。
并发的免锁实现
使用不同架构提供的CAS(Compare-And-Swap)指令实现的免锁互斥访问机制。这里需要知道,大多数编程语言只有最基础的一项操作是原子性的。通常有以下行为是原子性操作:
- 赋值动作(int x = 1;)
- 加减法(1 + 2)
- 自增/自减 ++/–
- 读取变量操作
但将以上组合在一起的行为并不是原子性操作,比如从一个变量中读取数据,对其做计算,并写入到另外一个变量中时(a = b + 1),这个并不是一个原子操作。所以针对这种语句是需要额外的机制来保证它的原子性,这也是免锁要实现的目标。
大多数编程语言和开源软件已经提前实现好原子操作的库,这种操作库提供了诸如atomic_read,atomic_write等操作去无锁化访问存在并发的共享数据,并且可以保证不出现并发问题。但这种原子操作存在一种约束,既是只能针对基础变量类型达到原子操作化,复杂类型的数据结构,比如结构体,类等等无法应用。除了上述的原子操作库,还有多生产者多消费者框架(FIFO queues、RCU)也是有类似的实现方案。
注意
存在ABA问题,也就是乱序执行发生时,CAS指令无法感知识别到原始数据已经被修改,只会根据它当时读取的值来做判断。这种时候只能添加屏障指令来让编译器和CPU不针对这里做优化,以此来防止乱序执行。
最小化加锁区间
首先,C语言的生态中有着不同类型的锁,不同锁的应用场景有着一定区别。使用合适自己场景的锁,并在对应的中尽量最小化这个临界区间。
自旋锁 spin lock
一直持有CPU资源的锁方案,自旋锁上锁之后,没有持锁的进程请求自旋锁是不会被调度出去,请求锁的进程会一直占有CPU资源做等待,直到有人释放了自旋锁。自旋锁大量应用在内核之中,用于关闭中断等不能被调度出去的场景下访问临界区资源。
互斥锁 mutex lock
和自旋锁相反,它是不会一直持有CPU资源的锁方案,互斥锁上锁后没有持锁的进程请求互斥锁会出现进程调度休眠,释放该进程的CPU资源给其他进程使用。相比自旋锁,互斥锁的阻塞状态不会有大量的CPU开销。互斥锁大量应用于一般的加锁场景中,包括各类常规的全局变量访问等等。
读写锁 read-write lock
除了上面两种最基础的锁,还有一种读写锁。内核中有大概有两种实现,一种是常规的读写锁rwlock_t,另外有一种特殊的为类似读写场景服务的锁rcu_lock,也被称为RCU锁。在实际使用过程中,大部分场景都会采用RCU锁去做多读少写的并发锁。网上有一张非常直观的图来区分这两种不同的锁:
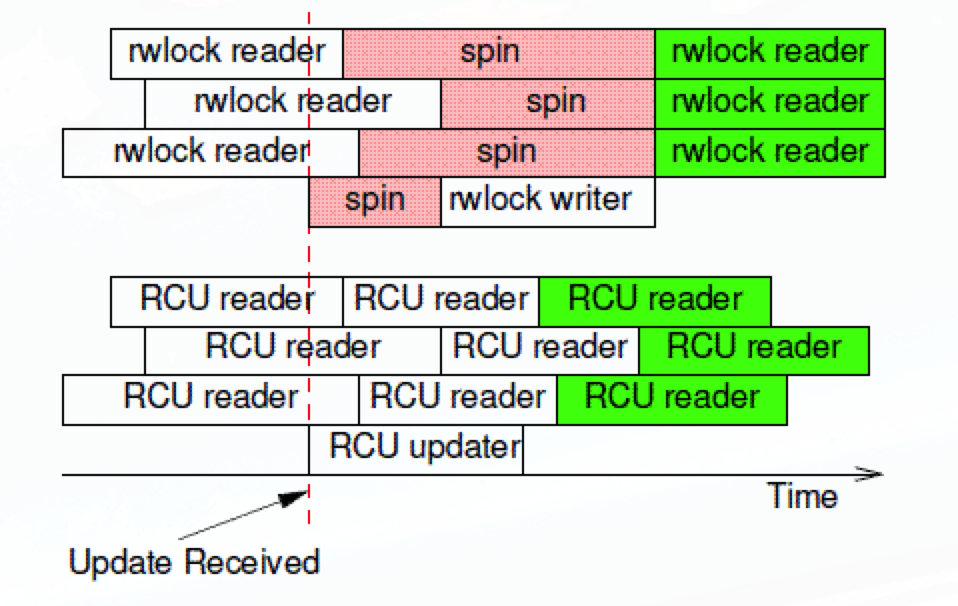
使用技巧总结
- 自旋锁应用在快速使用,快速释放的场景,由于该锁会消耗CPU资源的特性不宜长时间占有。自旋锁也可用在各种不能进入休眠或者调度的场景中,互斥锁一旦阻塞会使得进程进入休眠,而自旋锁就不会有这种问题;
- 互斥锁是所有锁之中开销最大的锁,不仅仅是锁本身的性能开销较大,还因为互斥锁在产生冲突阻塞之后造成的系统调度等一系列开销。所以在使用过程中,需要十分的仔细确是否有必要一定要使用互斥锁做临界区保护;
- RCU锁是Linux内核实现的一种特殊机制锁,用于解决常规读写锁开销大的弊病。因此,能使用读写锁的场景都能使用RCU锁直接代替,以此实现性能上的优化;
高效算法优化
位操作
使用位操作为基础的计算方式,在现代计算机中能够实现天然的并行化处理,寄存器中的bit位数值是可以一口气进行设置,而不需要进行多次分布计算。
用位运算设置一段bit区间,常规的做法是做一遍循环去逐bit设置值。但如果用位操作优化就可得到:
1 | //优化前 |
除此之外,现代CPU针对位操作还有极好的优化指令,能够快速提升运算速度,这也是做高性能计算的关键点。比如以下几个编译器中的内构函数:
__builtin_ffs:寻找无符号整数从低位开始的第一个二进制位为1的位置__builtin_clz:计算无符号整数中从最高位开始连续的0个数__builtin_ctz:计算无符号整数中从最低位开始连续的0个数__builtin_popcount:计算无符号整数二进制表示中1的个数
二分查找
二分的思想广泛应用在计算机的世界中,存在固定排序的数据中每次只看数据中间的值,根据与中间的值比较来进一步切分下一次要二分的区间,通过不断地二分比较以此来搜索最优的数据内容。这里就简单给一段示例代码说明:
1 | // input |
除了查找数据,有些时候在排查引入问题的commit提交时,二分commit内容也是一种很好的思路,这样只需要少量尝试就能知道有问题的commit是在什么区间之中,帮助我们锁定问题范围。比如git提供的git bisect命令。
函数拟合
如果学习过高数,我们能够知道有些时候能用一些多项式函数拟合一些计算较为复杂的函数表达式,当这些多项式函数的误差在可接受的范围内,可使用这种方式来做性能优化。
这里涉及到很多数学方面的证明和推导,这里就不过多阐述这种事情。(留给专业的人来做吧,我的高数也忘的差不多了)这里唯一需要注意的事情,拟合之后的多项式函数需要有相关的设计文档和代码注释来说明这些特殊表达式的含义,大部分看代码的人是无法直接理解这些多项式的背景和含义。
后话
憋了好久终于又来了一篇,想要平衡工作、学习、生活,对于一个社畜来说还是一件非常有挑战的事情呢。人的精力在工作上就被榨干的差不多了,还要抽空来跟踪最新的知识和学习其他额外内容就会显得疲惫,希望能够挺过来吧。(终于拖到2024年的最后一天发出来了)
坚持自己热爱的事情,相信自己脚下走的路。